First, some good news: Songbird is now in public beta! It’s amazing how stable things have gotten just over the last six months. And, significantly, it now features a Playback History API, which by the looks of things allows developers access to the entire play history of any song in a library, something that is crucial to the kind of deep library scavenging I’ve been pining for.
Since I last wrote, everything I see or read seems to inspire my half-baked ideas about the better ways we can browse our unmanageably large music libraries. After telling a friend about these ideas, he said:
Yeah, it’s actually really frustrating. I intentionally keep the number of artists on my iPod small so I don’t have to sort to find things I’m currently into.
Me too.
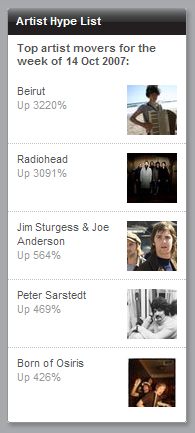
Then there are the people who are doing a lot of (real) work towards novel interfaces like the (hypothetical) ones I’m describing; Last.fm’s “Islands of Music” (explained here) demonstrates the kind of artist-similarity topology that would make browsing your library a more pleasant experience; Lee Byron explains in more detail how he developed that Last Graph infovis; necimal releases a Music Recommendations extension for Songbird that promises to use Last.fm’s data to find within your library artists similar to the one playing; and the Aurora project, part of the Mozilla Labs concept browser series, depicts a radical three-dimensional view of files and data with auto-clustering, which, if applied to a music library, would be nothing short of incredible.
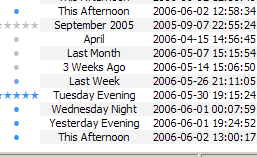
I’ve also thrown together a pitiful little mock-up of what Songbird might look like when you start it up with the kind(s) of extensions I’m hoping for:

The two core components depicted are the Start Page and the Timeline View. The Start Page I feel would be seriously valuable, one of the ideas behind all these blatherings of course being that one doesn’t always have a destination in mind when opening their music library. The Start Page would offer a number of convenient “jumping-off” points, pulling you into your library to explore it further — by artist similarity, maybe, or by play history proximity, after just a couple clicks.
The Timeline View is a zoomable timeline, shown here zoomed to a daily view. Zooming out could show you albums played within recent weeks; then months, quarters, etc. These albums might be sorted by Periodical Impact, something I explained in depth here; essentially they would be sorted not by the raw number of times they were played within any given period, but by how distinct they were to that period.
Even these meager ideas are leagues ahead of what’s available, and I’m not even a data analyst. Just imagine how a library’s play history data could be exploited by somebody trained in these things.
 The first two advantages are things you almost never need to do with music libraries. And the third has been supplanted by now-ubiquitous search boxes: if you know what you’re looking for, you search; and if you don’t, an alphabetized list is not the way to find it.
The first two advantages are things you almost never need to do with music libraries. And the third has been supplanted by now-ubiquitous search boxes: if you know what you’re looking for, you search; and if you don’t, an alphabetized list is not the way to find it.