I’m not an AI apologist by any means, but I’m frustrated by the muddled way LLMs have been marketed, portrayed, and used. I want to focus on the utility of them here, rather than the moral or legal implications of using copyrighted content to feed their corpora.
One of the first things we started doing when ChatGPT became public was, naturally, asking it questions. And for the most part, it gave us some pretty good answers.
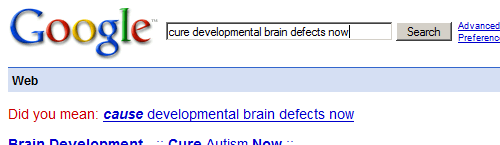
But as has been widely demonstrated recently — as Google, Meta, and others have begun grafting “AI” onto their search results — is just how wrong it can get things, and it has had us asking: Is this really ready for widespread adoption? Asking for arbitrary bits of information from an LLM’s entire corpus of text — like Google’s and Bing’s smart summaries — is demonstrably, hilariously, and sometimes dangerously flawed.
Over the last couple years, I haven’t really heard much from OpenAI themselves about what we are supposed to be using ChatGPT for. They seem more interested in creating the technology — which no one could seriously doubt is impressive — than in finding real-world applications for it. The announcement for ChatGPT didn’t tell us what to do with it (though it did emphasize that the tool can be expected to product false information).
I think the misconception about what ChatGPT is purported to be good at can be attributed to the name and the UI. A chat-based interface to something called “ChatGPT” implies that the product is something it isn’t. It’s technically impressive, of course, and makes for a good demo. But chat doesn’t play to its strengths.
The reason any given LLM is even able to wager a guess at a general knowledge question is the corpus of text it’s been trained on. But producing answers to general knowledge questions is a side-effect of this training, not its purpose. It isn’t being fed an “encyclopedia module” that it classifies as facts about the world, followed by a “cookbook module” that it classifies as ways to prepare food. It was designed to produce believable language, not accurate language.
Where it does excel, however, is at coming to conclusions about narrow inputs. Things like Amazon’s review summaries; YouTube’s new grouping of comments by “topic”; or WordPress’s AI Feedback — these take specific streams of text and are tasked with returning feedback or summaries about them, and seem to work pretty well and have real utility.
These examples demonstrate two similar but distinct facets of LLMs: Their role as general knowledge engines, or “oracles,” and as input processing engines, or “analysts.” When we ask ChatGPT (or Google, or Meta) how many rocks we should eat per day, we are expecting it to behave as an oracle. When we ask it to summarize the plot of a short story or give us advice for improving our resume, we are expecting it behave as an analyst.
Signs point to Apple using LLMs primarily as analysts in the features to be announced at today’s WWDC, processing finite chunks of data into something else, rather than snatching arbitrary knowledge out of the LLM ether.
The allure of ChatGPT as an oracle is of course hard to resist. But I think if we recognize these two functions as separate, and focus on LLMs capabilities as analysts, we can wring some value out of them. (Their environmental impact notwithstanding.)